On scientific software - reproducibility
Well I had to expose this series of blog posts before I had them all done because of this:
Most scientists, even the ones doing research relevant for policy, can't afford to hire professionals for their software development. So you get the coding equivalent of duct tape and chewing gum: Works, but looks crappy.https://t.co/593KxGC2SX
— Sabine Hossenfelder (@skdh) June 10, 2020
Not only the nature news item validating Ferguson’s simulation, but also Sabine Hossenfelder’s beautiful summary, which basically nailed what I was trying to say in one tweet!)
So, now it is time to talk about “code” quality, but first, let me start with one of my favourite xkcd cartoons. In this instance the code is an app and the information source is independent of the code. It’s pretty obvious that code quality cannot deliver useful outcomes in and of itself.
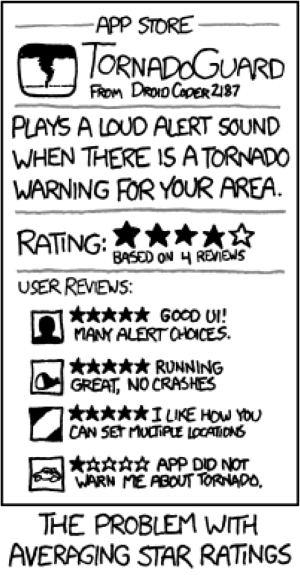
- When software quality is completely irrelevant and it is the information source that matters!
Let’s also consider the substance of the Nature news item which can be summarised with a couple of quotes:
The successful code testing isn’t a review of the scientific accuracy of the simulation, produced by a team led by mathematical epidemiologist Neil Ferguson. But it dispels some misapprehensions about the code, and shows that others can repeat the original findings.
Which speaks to the XKCD example - good code depends on the inputs, in this case a combination of algorithms, parameters and data. This reproducibility test tells us nothing about the validity of the scientific conclusions.
The amount of time researchers have to spend either helping people use their software or refuting claims stemming from its misuse is a “big worry” among many academics, says Neil Chue Hong, founding director of the Software Sustainability Institute in Edinburgh. “There are ways you can run the code that mean you won’t get sensible results, but the researchers who use the code know what those ways are,” he says. “It’s like you or me being given a Formula One racing car, and being surprised when it crashes when it goes around the first corner.”
This is really saying two things: building on the shoulders of giants is facilitated by tutorials from giants, and “code is a tool” and “there is validity in developing expertise in tool-use”. But unfortunately the way Neil has been quoted here introduces an implied subtext which is “if only the author did something better, we - you or me - could all use formula one racing cars”. Never mind exactly what that something better might be, the conclusion that we could then drive the car past the first corner might or might not be true, but us amateurs are unlikely to win any races no matter how easy it is to learn to drive - practice and expertise matter.
The important point is the first one, if giants help us use their tools, appropriate others can stand on their shoulders more efficiently. You or me might be an appropriate other, but we might have to expect to have done some training before we get the scarce attention of giants. That is, we should not expect the level of code documentation required for industrial software engineering.
This expediting science is also the argument Gavin made for why we ask for code to be shared with our papers. I am not sure that Gavin really meant “and in doing so, it means anyone can run your code without some further interventions”. (I am sure he can tell us what he really meant, and if he does, I’ll add a link here.)
There is an established belief that having access to the code provides more grist to the peer review process, and in that way would weed out the scientific chaff. However, except in relatively trivial cases, that’s exceedingly unlikely. In the same way that no-one really attempts to rework all the complicated mathematics in most papers as part of peer review, few if any reviewers attempt to run complex codes, and in most cases, are unlikely to be able to do so - and if the code has any complexity it would be mostly impenetrable without far more time than is available to reviewers (no matter how beautifully it is written).
What people do want peer review to deliver is some confidence that the method was appropriate, that is, that the design was suitable, the tools were appropriate, and enough information is available to repeat the analysis and/or any repeatable part that depends on a digital laboratory. In the latter case, ideally we want to be able to facilitate the reproduction of measurements and experiments, because that’s one of the key tenets of science. As Frey et al (2012) point out
The integrity of science as a discipline rests on the ability of scientists to reproduce the claims of others” (Poulter, 2009))
and doing that depends on experimental detail:
Faraday’s laboratory notebooks are also remarkable in the amount of detail that they give about the design and setting up of experiments (from Peter Day, 1999)
I would argue that having access to code doesn’t actually directly address either of these requirements. Far from it. Being able to replicate the running of the code would replicate whatever was good and bad, and doesn’t really address either “the claims” or the “design”, that is, what the numerical calculations were intended to achieve.
What does address those requirements? Well, having access to the analysis code certainly allows one to understand how the analysis was implemented, and might allow one to repeat the same analysis with different data, which is an exercise which would address the claims issue.
However, for the digital laboratory part of the problem, I think it is far more important to have a detailed understanding of the experiment design, so that the experiment itself can be repeated, with different software or the same software on different inputs and/or spatial or temporal domains. (Full disclosure: I have invested heavily in developing tools to document numerical experiments involving simulation).
Well this is getting long again. I still haven’t addressed quality, so more soon! There is still much to say about quality and when and where we (the scientific community) should (and often do) invest in well engineered code (a phrase I am going to use to distinguish from quality). In doing so I hope I’ll alleviate the concerns of those of you who think I’m denigrating the importance of investing in well engineered code, or in good software engineering practice - I’m not. I’ll also address a bit more my thoughts around what journals could and should require for code availability.
Meanwhile in a vain attempt to minimise the responses along the lines of “but unit testing” etc - those of you who know me up close (in the academic sense) will know that I’m actually a bit demanding about version control and unit tests and modularity and many other methods of best practice in software development - but nothing is free and everything is a trade-off, so getting the right person to do the right thing at the right time for the right reason is more important than doing something for the sake of best practice!