Metadata, XML and Deja Vu
It’s funny how some concepts and issues are repeated in multiple communities. Recently I attended a meeting called “Activating Metadata” (agenda,talks) held at NIEeS. The sharp eyed amongst you will have noted that the link for the talks is …/metadata2 … talks from an earlier event are here. There have been other meetings on a similar theme which don’t seem to be archived.
These metadata events are both stimulating and boring in equal measures. Regrettably we go over much the same ground every time (boring), but I learn new things when I meet new communities (stimulating). Fortunately this second meeting was a very different community, being primarily geographers and users of geography data (in a loose definition of the sense). Of course they have their own vocabularies, and needs for specific metadata.
Anyway, there seemed to be a feeling amongst some that metadata standards were a hindrance to academic use of data, and that more “of the right sort of metadata” was needed. While I would obviously argue that more metadata is needed in just about any context, the usual argument that “the standards didnt do it for me therefore I wouldnt use them” was frustrating. Since the meeting, I’ve written to one of the participants, and amongst other things I wrote:
There are solution frameworks out there, and if one doesn't want to use them, one simply contributes to the proliferation of options and consequent user confusion. Most importantly, one needs to understand that standards exist not as an effort to constain all possible metadata, but to constrain those elements where there is a chance of commonality (and interoperation between groups). You're free to produce whatever else you like that is relevant to your own user community.
In quite a different context Dare Obasanjo of Microsoft has been discussing the new buzzword microformats of XML. This discussion is about whether or not folk should be introducing their own tags into XML documents (with or without namespaces). There seems to have been much blognoise on the topic, but I think Derek (Only This and Nothing More) got it right:
Ever sit down at a table with a number of experts in a field that you do not know? They may be speaking English, but that doesn?t mean you understand what they are talking about. If you try and force them to speak in laymen?s terms, the efficiency of the information exchange drops dramatically. Specific languages are sometimes necessary. Individual specialties within Math and Computer Science all have customized definitions of terms, that sometimes conflict. Each specialty evolved it?s terminology to enable efficient, unambiguous communication between specialists in that field. Custom grammars are a necessity for efficient communication. Language reduces to the least common denominator of the intended listenership. If an application expects generic tools to process it's data, then it should use a well known standard. If local efficiency (or development or data) is more important, then use custom formats.
Which reads like just the same thing I was saying in the metadata context, hence the Deja Vu.
Metadata standards such as ISO19115 are being designed with just this structure in mind. Indeed, ISO19115 has the following view of how it should be used:
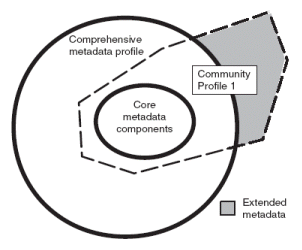
Similarly, XML documents are built with xml namespaces in mind, and so the XML syntactical rendering of ISO19115 (the almost mythical ISO19139) will be built to allow communities to build such application profiles. I think that’s what my geographer friends and the xml microformatters need to do: Build application profiles of existing standards, with all their own information built in as extensions over the core. Sure not every application will know what it’s about, but all applications conforming to the core standards ought to be able to recognise elements in common, and specific applications exploit the extra information.
How one stores this information is a moot point, flat files, databases, GIS systems whatever, but when we exchange the stuff it’s going to have to be with XML. And with XML, we’ll use namespaces. We fully expect the application profiles of standards to pull in stuff from other namespaces …
… which in the microformatter argument leads to questions about whether or not entries should have the same names in all application profiles. Of course not! We just don’t all use the same names for everything, but where we do have communities intersecting we can build ontologies (which are just sophisticating mappings between terms that we understand). We can then use tools to do conversion between documents, exactly as argued in, for example, Dare’s first article linked above. But, I think the microformat principles linked in the definition above, hold well in the scientific metadata world too:
- solve a specific problem
- start as simple as possible
- design for humans first, machines second
- reuse building blocks from widely adopted standards
- modularity / embeddability
- enable and encourage decentralized development, content, services