The anatomy of a mip
We’re in the process of documenting a specific model intercomparison project (MIP) for the purposes of the Rapid programme. It’s the same issue we have for CCMVAL[^1], and for metafor in general.
The issue is what metadata objects need to exist: Never mind the schema, what’s our world view look like? It looks something like this:
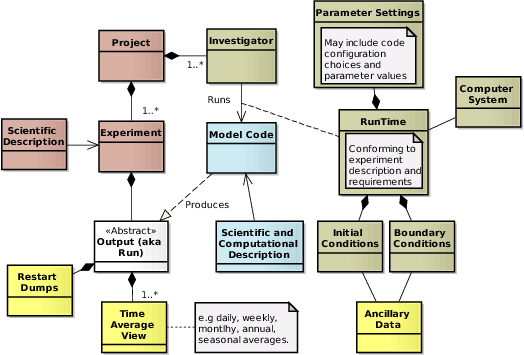
Beyond the classes and their labels, one of the key features of this diagram is the colour of the classes, which is meant to depict governance domains of the information (sadly, at the moment, the governance of the metadata itself is all down to us).
- The brown classes (project, experiment, scientific description) essentially come from the project aims.
- The blue classes (the model and it’s description) are generally the integrated product of development and descriptions over a number of years by a modelling group.
- The yellow classes are the data inputs and outputs. In principle we can auto describe the data itself from the contents of data files, but there is context metadata needed. In the case of the output Time Average Views which are the moles:granule objects which we store in our archive, the context metadata is all the stuff depicted here. In the case of the input Ancillary1 Data, we hope the context metadata already exists.
- The interesting stuff, which is dreadfully hard to gather and which may consume the most time, is the khaki stuff - in comparison to the blue material which we hope is rapidly slowly changing, the khaki material is different for every run.
Now some folk go on and on about repeatability of model runs. Sadly, very few model runs are bitwise repeatable, not only is there not enough metadata kept, but generally the combination of model code, parameter settings, ancillary data, and computer system (with compiler) is generally not even possible to re-establish.
Personally, I think that’s ok (it’s just not practicable for sufficiently complex model/computer/compiler combinations if the elapsed time is anything much above months), but what’s not ok is for a model run to be unrepeatable in principle: that is someone ought to be able to add a new run which conforms to the experiment and for which it is possible to compare all the elements depicted here. We ought to have kept the data and the metadata. We really ought to, and we ought to understand how to construct a difference.
Hence metafor, but right now, we just want to make sure we describe our Rapid data … [^1]:that link doesn’t exist at the time of writing, but it will :-)
trackbacks (1)
anatomy of a mip - part2 (from “Bryan’s Blog” on (on Wednesday 18 June, 2008))
… discussing the UML describing such projects (which appeared in the previous post). In doing so, we managed a few simplifications and fixes to my UML …
-
with apologies to the Met Office, this is a slightly different use of the word Ancillary. ↩