simulation documents
In my last post I was discussing the relationship between the various elements of documentation necessary to describe the simulation workflow.
It turns out the key linking information is held in the simulation documents - or should be, but for CMIP5 we didn’t do a good job of making clear to the community the importance of the simulation as the linchpin of the process, so many were not completed, or not completed well. It’s importance should be clear from the previous figure one, but we never really promulgated that sort of information, and it certainly wasn’t clear from the questionnaire interface - where the balance of effort was massively tilted to describing the configured model.
{kind=link}
Looking forward, it would seem sensible to separate the collection of information about the simulation from the collection of information about the configured model (and everything else). If we did that, the folks running the simulations could get on and document those in parallel with those documenting the models etc. It would also make the entire thing a bit less daunting.
To that end, I’ve tried to summarise the key simulation information in one diagram:
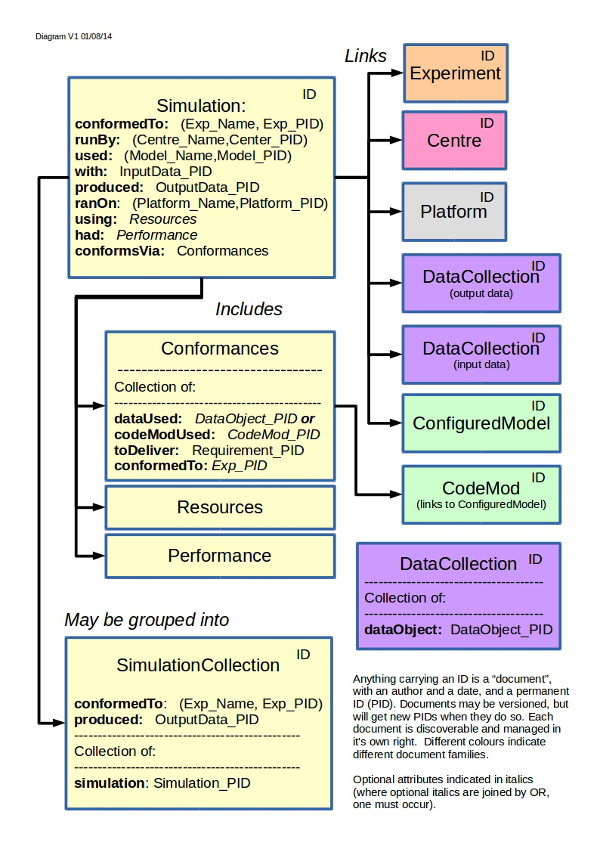
(Like last time, this is not meant to be formal UML, but something more pleasing on the scientist eye.)
The key information for a simulation appears in the top left box, and most if it could be completed using a text editor if we gave folks the right tools. At the very least it could be done in a far easier manner to allow cut and paste. The hard part was, and still would be, the conformances.
(For now we don’t have a specification for how to describe performance and resources, but these are not expected to be hard, and the ground work has already done by Balaji at GFDL.)
One tool we need to provide folks to make the best use of this information would be a way of parsing the code mods and the configured models to create a sort of key,value list which described any given configured model in a way that could be compared in terms of mathematical distance from another model. Such a tool would enable the creation of model genealogies (a la Masson and Knutti, 201) in a completely objective way.
One thing to note is that the simualtioncollection documents allow one to collect together older simulations into new simulation collections, which means that we ought to be able to develop simulation and data collections which exploit old data and old models within the ensembles for new experiments.
(I should say that these blog posts have been a result of conversations with a number of folk, this last one based on a scribble on the back of an envelope from a chat with Eric Guilyardi.)