Formalising Information Model Development
Our metafor project is trying to establish a formal methodology for constructing UML, working with that UML in a team, and building multiple implementations using combinations of RDF and XML-Schema.
There are some interesting problems to overcome:
- Establishing UML conventions that will allow code generation.
- Dealing with version control of the UML. (And dealing with different versions of XMI).
- Dealing with code generation itself.
(In this context, code generation is simply the generation of XML-Schema and/or RDF which contain appropriate data models).
I’ll try and address these in a series of posts. (I was once told that it’s a bad idea when being interviewed live to say something like “there are three points I want to make” because you’re bound to forget the third under the pressure of a live interview. I suspect I have form for listing things I will post about, and never getting around to doing so, which must be the blogging equivalent, and thus something to be avoided. We’ll see.)
But before we do this, there are some vocabulary issues that need expansion. Metafor is about building a “Common Information Model” (or CIM) for climate (and other numerical) models. Such models describe the earth system using mathematical equations encoded as computer programmes, and are used as part of activities to produce data (often starting with various data inputs). I’ve described some of this before. Like most folk entering this sort of activity I’ve typically blundered straight into defining things without thinking about the process clearly. Perhaps I’ve learnt a few things along the way about why that’s not so clever …
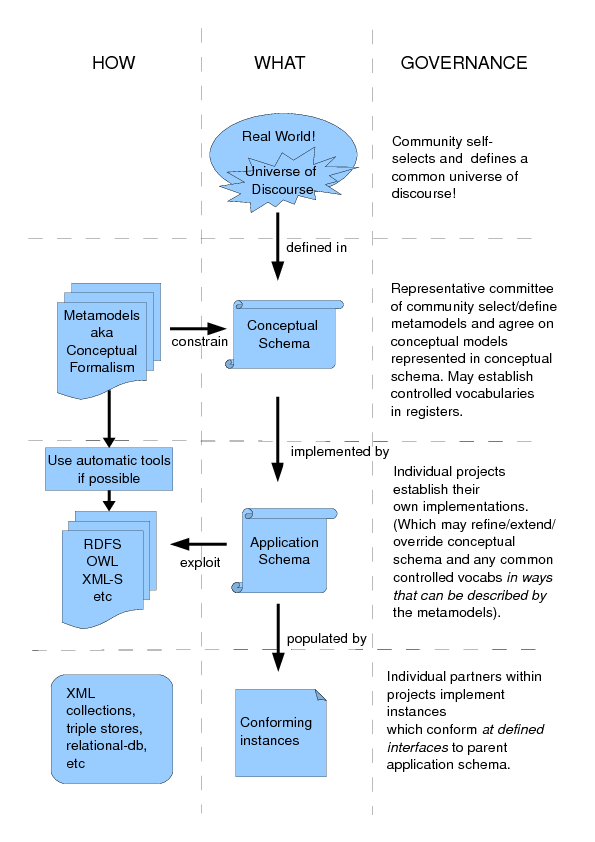
The first step before we construct any conventions is to consider the structure we’re actually talking about. Much of this is really well documented in section 7.4 of ISO19101 and in the entirety of ISO19103 (Geographic information - Conceptual schema language) but since those documents are not easily accessible, we’ll try and summarise.
(Note that we’re using model in two different ways: in the context of “information” and the the context of “simulations”, hopefully the context will help make clear which is which).
Firstly, from wikipedia we have :
... a model is an abstraction of phenomena in the real world; a metamodel is yet another abstraction, highlighting properties of the model itself. A model conforms to its metamodel in the way that a computer program conforms to the grammar of the programming language in which it is written.
So, to construct our CIM, we need to construct a metamodel, which provides some rules about how to construct it. Clearly our metamodel includes the exploitation of UML, but it needs to be more than that, otherwise we’ll not be able to build something we can serialise into RDF and XML without a lot of human interaction. It’s that “more” that we need to consider in a later post … but meanwhile, we also need to relate the metamodel, and our own information model with their actual application in schema, and we also need to remember we live in a world where others are doing similar things.
I’ve tried to summarise all this in a customised schematic version of figure 4 in ISO19101: