the publication ecosystem
Cameron Neylon drew my attention to an absolutely fascinating set of figures that appeared in a Research Information network paper last year (pdf). You should read Cameron’s post, it’s interesting in it’s own right for anyone interested in the place of peer review in the firmament. However, what I wanted to here was abstract some rather interesting numbers from the report. They all appear here:
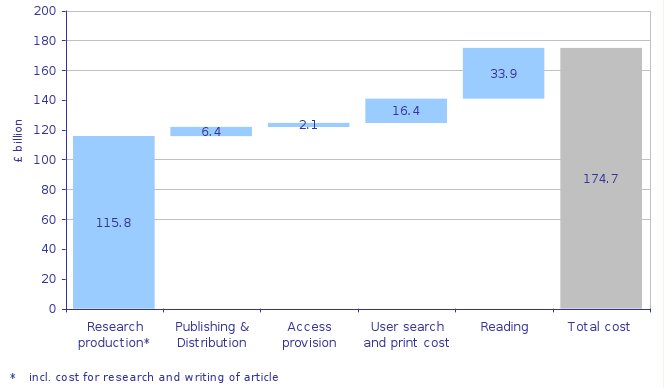
This figure requires a bit of explanation, which you’re not going to get here, aside to say the numbers are an estimates of the totals spent globally in the entire process of scholarly communication and research. Note that the cost of “reading” is split out from the cost of “doing research”, if you really wanted to know the cost of research itself you might add those two figures together. Amongst the interesting conclusions that we can draw is that the cost of the publication machinery, from submission to consumption via the eyeballs, is roughly 1/7 of the total costs of the global research ecosystem - and half of that is the cost of searching and printing out the resulting documents. Deep in the model, we find an assumption that it takes 12.5 minutes search time per article and that dominates the search/print cost. I’m not quite sure where that number comes from, but it’s very plausible to me. Another interesting number buried in the publishing cost is 2 billion on peer review, i.e. peer review is of the order of 1-2% of the total cost of research.
It’s not a great leap to wonder if those large figures on discovery and reading are the consequences of
“publish or perish” coupled to the “smallest publishable unit” leading to far to much crap literature to wade through in many disciplines. (However, to be fair, as one who always used to argue to my graduate students that one hasn’t “done anything” until one has published it, simply bashing the amount of material out there isn’t the whole story.)
Anyway this piece of work prompted me to wonder if anyone has actually quantified what proportion of research time/effort/budget is spent dealing with data handling? I’ve heard lots of anecdotes, and I’ve created a few guesstimates myself, but I wonder if anything half as authorative as this report has been done?1 If so, then the obvious question to ask would be whether those numbers would support more or less of a professional data handling infrastructure?