Provenance, processes and O&M
This is by way of a summary of the first of a bunch of recent discussions about MOLES. The context is that of the upcoming ISO19156 Observations and Measurements standard which boils down to the material and concepts which surround this high level view of an observation:
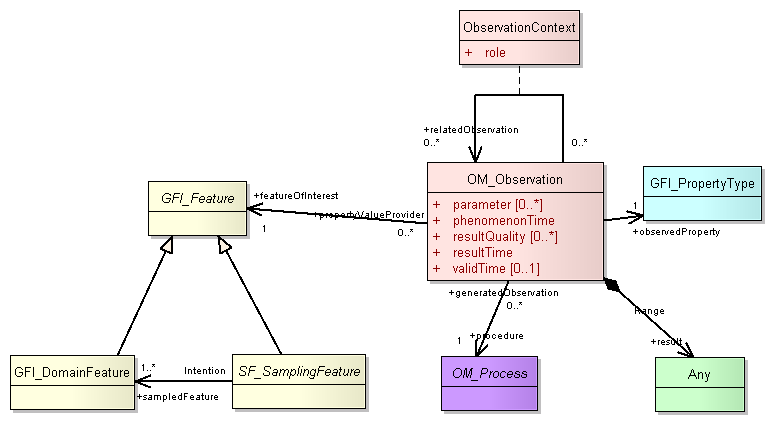
I’ll probably add quite a lot more. This is work in progress, so these notes are thoughts, rather than results. The authoritative source for MOLES is the moles trac site.
On Processes
As part of our analysis of metadata objects which link environmental sciences, MOLES, we need to address the process by which observations are made.
The upcoming O&M ISO standard has two relevant classes:
- OM_Process which defines the procedure by which an observation delivers a result, and
- SF_process which transforms a sampling feature into another sampling feature.
Both have important roles in understanding the provenance of an observation.
If we concentrate mainly on the former, then within MOLES we see the necessity for two sorts of sub-process:
- One associated with the acquisition of a result (by an instrument or observer, and which may involve some SF_process substeps), which we call MO_Acquisition, and
- One associated with processing to produce a result. The latter we call MO_Computation (generally the latter will involve taking some inputs, and producing some outputs, but it could also be an ab initio simulation).
In the context of the current version of MOLES we see MO_Acquisition as being a specialisation of MI_Operation (making a direct link to ISO19115 part 2), and MO_Computation being a specialisation of LE_ProcessStep (and thus directly linked to ISO19115 itself). Noting the way that O&M refer to ISO19115 there is an argument that we should simply compose such classes in, as to which is “right”, I think that should probably come back to addressing the following questions:
- Why appeal to standards based classes? (To make it easy for reusability, and interoperability)?
- Given the answer to the first question, which of the methods makes it more easy?
Either way, it would now seem that MOLES SF_Process specialisations should be composed into MO_Acquisition.
On Scope
Thus far MOLES has really only addressed coverage type observations (those which have coverage type results) properly.
We really need to work through the BODC examples, and some specimen acquisition examples. Tree rings might be an excellent target for doing that.
On Computation Environments
The Metafor construction is that: An “activity” “uses” “software” “deployed” on a “platform” to produce “data”.
If we try and put that in the context of MOLES, one might start by thinking carefully about the distinction between an algorithm, and the software which implements it.
Within Metafor we have spent rather too long a time being confused by using the same classes to describe both the algorithm (which is essentially what the CMIP5 questionnnaire is doing) and the actual software (which is how the very same classes will probably be deployed within ESMF).
We had better make sure that both MOLES and Metafor make the distinction, even if we use the same classes to compose in their attributes.
LE_Processing has two relevant attributes and associations:
- softwareReference: CI_Citation[0:1]
- algorithm: LE_Algorithm [0:1]
So the conceptual distinction has been made, so to that end, if we specialise LE_Processing to MO_Processing, we can use softwareReference to point to the software description, and specialise LE_Algorithm for the scientific description using MO_Algorithm
The software description would then point to a standalone MO_Algorithm description, and we should probably give MO_Algorithm an attribute of
- usage: <Description> or <Implementation> and expect the former to be used when it is used as an algorithm and the latter when pointed to by softwareReference.
That leaves the issue of what to do with the deployment and platform concepts within Metafor.
LE_ProcessStep has a processor argument, but I suspect that is best used to point at the human(s) responsible for the processing.
So we might think we should add to the MO_Processing class an attribute (“uses”) to point at a MO_ComputingPlatform. However, we can imagine a situation where there is a human who implements an algorithm with pencil and paper, so the absence of this attribute should indicate that the human responsible for the processing was the computer …
If I remember the justification of the distinction in metafor between deployment and platform, it was to allow the distinction between different compilers etc on the same hardware. I now think that’s probably not an intuitive way to do it, probably better to think of different compilers on the same hardware as different versions of the same platform. (And the facility aka organisation at which that platform lives should simply be a CI_ResponsibleParty attribute of the platform.)
Common Patterns
So the idea of running a computation at a facility on a platform has been expanded upon above. Is that a common pattern when we bring instruments being deployed at a location? We need to just revisit that and see if it’s all consistent and sensible, or whether we are handling the two kinds of processes (acquisition and computation) in different ways. We might also need to consider how we deal with subprocesses being carried out at different institutions than the parent process - as will undoubtedly be the case for laboratory analyses.
Currently we have MO_ObservationFacility as a specialisation of MI_Platform … and MO_Platform and MO_ObservationSite as specialisations of that with the former being the operatedAt assocition form the latter.
If we wanted to bring these two uses of platform (MO_ComputingPlatform and MO_Platform) together, then it would be better not to specialise from MI_Platform directly, and do some composition from a standalone class. Food for thought.