Digital Earths - The fourth phase of (ESM) modelling maturity?
I recently introduced my definitions of “Digital Twins” and “Digital Earths” and concluded with the statement that I thought there was scope to do good thing in (these new) twinning activities. There are two such axes of scope: scientific and technical. Here I want to discuss the latter (and it’s impact on some science). In the discussion which follows I’m talking about Earth System Models (ESMs), but the arguments could apply to many other modelling activities (e.g. epidemiological modelling).
The Four Phases of Modelling Maturity
When we are talking about modelling as an activity (as opposed to models), and we are talking about models which aim to describe the real world as it is, was, or might be, then we obviously have to compare the model simulations with reality. Less obviously, we have learnt we have to compare those simulations with the simulations made by other models. What does all this “comparing” entail? It entails comparing lots of different variables in lots of different ways, and with anything like a complicated model, involves lots of different people who have expertise in different processes represented by those models.
This starts out on a local scale. People know how to use the output of their models and analyse the output by comparison with data they have already, or obtain from elsewhere:
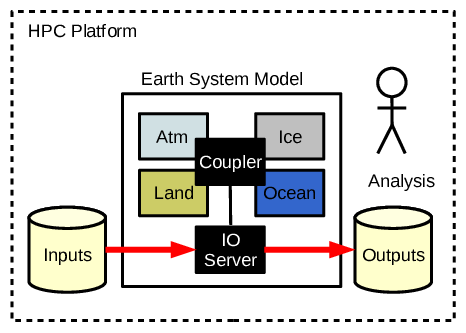
- Phase 1: Individuals and groups within an institution analyse the output data from their complicated model
Before long it becomes necessary to compare simulations between groups, and people share output data files. Initially they share files “as is” and describe what their data are and how to work with ad hoc documents and emails (and maybe a wiki or two).
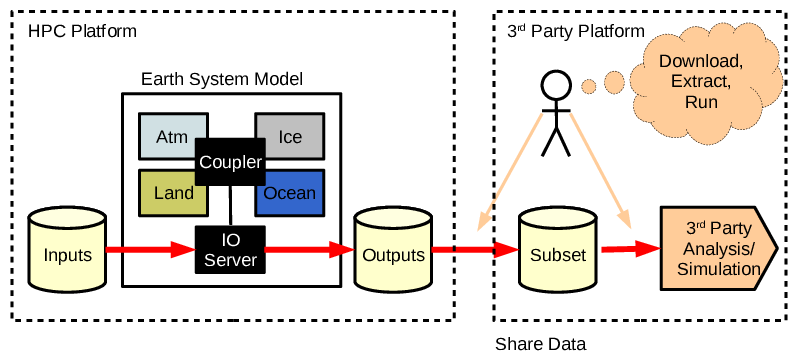
- Phase 2: Individuals and groups share data with close colleagues in other institutions and share information about what the data is and how it is formatted using private communications (e.g. email).
That model of sharing and collaboration doesn’t scale though. At some point modellers in one group will be using data from groups where they do not have personal contacts. Analysts may not even be in modelling groups.
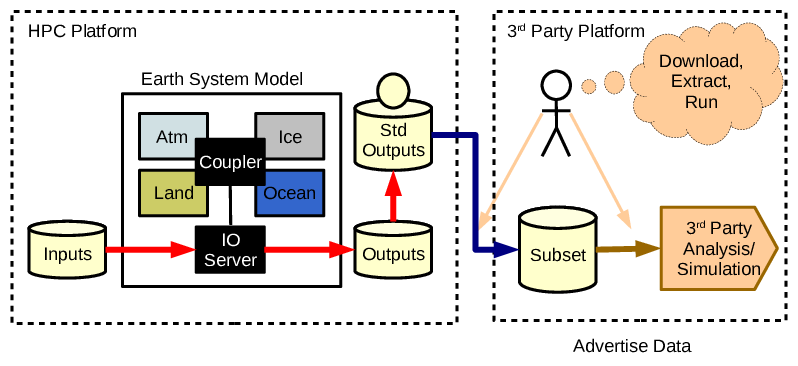
- Phase 3: Data producers and data consumers groups are not (well) known to each other. Standardised data files are described using machine readable catalogs and shared using standard protocols.
At this point we probably have peak “modelling groups”: people producing data are not seeing all the usage and all the benefit of producing the data in the first place. Many users find the “standardised data” insufficient/inappropriate for their application and there is no head room for the modellers to address their requirements. Data volumes are problematic for moving. The benefits of model diversity in terms of independent alternate computational representations of the real world are probably not scaling with the number of models.
Some models and modelling groups might take one last step, and move from advertising data alone to additionally advertising how some collaborators can take advantage of numerical experiments. A limited number of collaborators may be able to take advantage of concurrent scheduling and standardised data interfaces to get higher temporal resolution and/or special data products that will not be persisted beyond the run time. Applications might use these data to drive other models, they may support fancy visualisation, but a key characteristic is that they need to be run at the same time1. Collaboration now requires advertising experiments as well as continuing to advertise data. This, for me, is a digital twin.
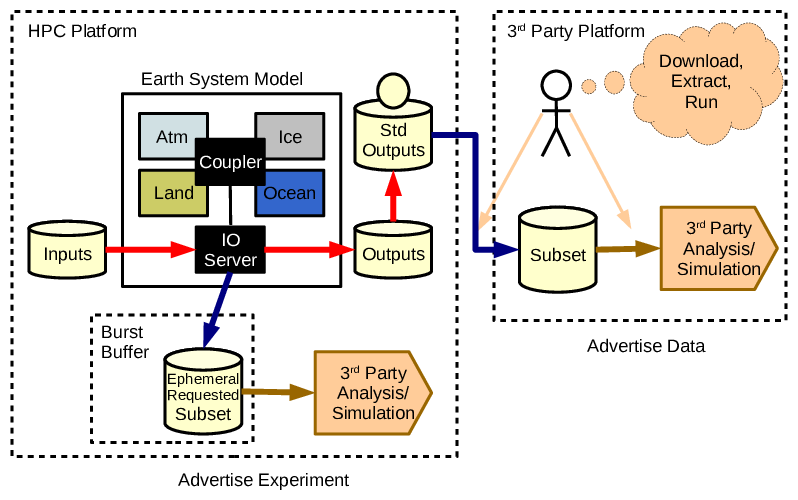
- Phase 4: Two different modes of collaboration: advertise experiments to exploit ephemeral data during simulations, as well as supporting data use by third parties using standardised data products.
(That limited number of collaborators can of course themselves represent larger communities that they serve via advice, publication, standardised data, or any other mechanism.)
Digital Earths
So, for me, an ESM based digital earth is a not just a model which has reached the fourth stage of maturity. It is an activity which involves situations covered by an experimental design which is not just that promulgated by an ESM community, but is co-designed by the wider community who need to collaborate on exploiting the ephemeral data.
The underlying assumption here is that the resources needed for an ESM based digital twin will be large (especially one with a global domain), and that we need to maximise both the utility of the experiments, and their user communities. In this case the user communities could well be those closer to being able to exploit ESMs to deliver actual societal outcomes as well as other physical science groups.
Postscript
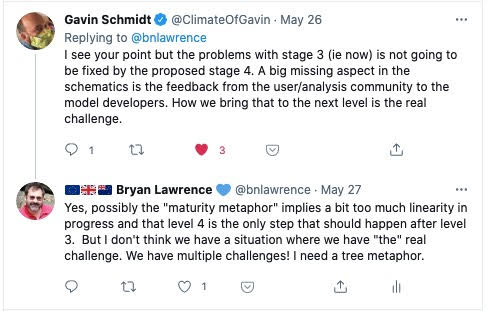
Update: After I posted this we had an interesting exchange on twitter:
-
How we establish these interfaces, what they might look like, how “concurrent models” are scheduled and run, and how long before we get agreed methods which can become standardised is a topic for another day. ↩